When Dependency Inversion gets too big
I was on a Golang Interpreter journey, let me tell you how it went. Examples will be mostly from a worker reading messages from a queue and processing them.
How it always starts
When you initiate a new project and implement cutting-edge architectural patterns such as hexagonal architecture, vertical slice, dependency inversion, etc., the process of building your application is quite manageable in the early stages. You're dealing with one application across two environments: development and production. The code implementing dependency inversion, which I'll refer to as the build process, for a simple processor designed to read from a queue, might look something like this:
func Build(cfg config.Config) (Processor, error) {
repo, err := mongoRepo.New(cfg.MongoAddres)
if err != nil {
return nil, err
}
api, err := api.New(cfg.Api.Addr)
if err != nil {
return nil, err
}
return processor.New(repo, api)
}
At this stage, everything appears straightforward and understandable, allowing you to clearly comprehend the architecture and flow of operations.
Some time later
Application grows, you need to start caching data, you need to write events to a queue so other systems might react to what you are doing. You start creating application per data source, so they can scale according to each source requirements and if fail, the fails are isolated, let's say 5 different sources. Number of events in sources grows and you have to start throttling incoming requests on dev. One day business comes in and says: we need another deployment of this application for a different client, it will have slightly different business logic and technical requirements than current prod. It's great, there is a lot of code reuse, all components do one thing very well. One day you get a bug report. You ask yourself how exactly the application on the first prod that is reading from queue 3 is built? Build package now has 1000 lines of if and switch statements that depend on configuration. It's hard to follow. Message is going through 10 components/layers of abstraction before data is written to the database. Composition is too strong in this one.
One day
One day I was doing a presentation to my fellow engineers about dependency inversion and how it's used to build composable and reusable applications. I had handbuilt a tree of dependencies being injected into each component based on configuration:

Creating the tree was tedious. In the presentation I said "this tree could be built automatically" and that moment was a seed which grew into a project I want to tell you about. The presentation happened around the time I went through the Writing an interpreter in Go book.
Idea
Write an interpreter of Golang which doesn't operate on objects like int or string, but one operating on dependencies:
Normal interpreter:
> add(1, 2)
3
Dependency interpreter:
> add(1, 2)
add
| |
1 2
Normal interpreter:
> repository = mongo.New(cfg.MongoAddr)
.. basicService.New(repository)
Service struct:
Dependency interpreter
> repository = mongo.New(cfg.MongoAddr)
.. basicService.New(repository)
basicService.New
|
mongo.New
|
cfg.MongoAddr
This dependency interpreter would output a representation of a tree which can be rendered graphically. Such interpreter can be used to interpret the build package of an application when supplied with configuration. Result would be a dependency inversion tree of components.
Plan
- Get a build package and configuration,
- flatten build code: remove all if and switch statements using configuration,
- interpret flat code building the dependency tree,
- enhance tree nodes with additional information,
- render the tree.
I went with a step by step solution instead of processing everything at once, so I can inspect byproducts of every step to make debugging easier. In hindsight this decision saved me a lot of time.
Execution
I went with the approach of writing code that solves minimal build. Took the simplest service from our project and added features to render its build, then took the next build in complexity and solved it. We have 9 applications with distinct builds. Each build required some work to get it to render.
Flatten
Relatively simple AST traversal. Inspect all block statements, if if or switch are found, evaluate condition and replace the conditional node in a tree with statements from inside conditional node that would be executed during build runtime. Use configuration to resolve conditions.
For cfg.X = -1 this code:
var y int
if cfg.X > O {
y = 3
} else {
y = 5
}
fmt.Println(y)
after flattening becomes:
var y int
y = 5
fmt.Println(y)
Condition Evaluation
Evaluation is done by a third party library. I had encountered a switch statement that switches over URL schema:
// some build code
schemaURL, err := url.Parse(cfg.Recipe.Source)
if err != nil {
logrus.Fatal("Failed parsing schema repo uri")
}
switch schemaURL.Scheme {
case "dir":
...
case "api":
...
There is url.Parse needed before condition can be evaluated and evaluator that I used doesn't have Golang standard library implemented, but it supports injecting functions. The problem was that it doesn't allow for injecting functions with "." in the name. I had to hack it. I replaced occurrences of url.Parse( with urlParseQQQ( and wrote urlParseQQQ function, also had to write and inject len():
func Prepare(expression string) string {
return strings.ReplaceAll(expression, "url.Parse(", "urlParseQQQ(")
}
var Funcs = map[string]goval.ExpressionFunction{
"urlParseQQQ": func(args ...interface{}) (interface{}, error) {
u, err := url.Parse(args[0].(string))
if err != nil {
return nil, err
}
bytes, err := json.Marshal(u)
if err != nil {
return nil, err
}
var final map[string]interface{}
err = json.Unmarshal(bytes, &final)
if err != nil {
return nil, err
}
return final, nil
},
"len": func(args ...interface{}) (interface{}, error) {
arg := args[0]
switch arg := arg.(type) {
case []interface{}:
return len(arg), nil
case map[string]interface{}:
return len(arg), nil
case []string:
return len(arg), nil
case string:
return len(arg), nil
case []int:
return len(arg), nil
default:
return nil, fmt.Errorf("unknown type in len %T", arg)
}
},
}
In later stages of development I found an evaluator which could do std but I was too lazy to switch, this beauty was good enough.
Leaving some ifs
It turns out that you can't just remove all ifs without doing full interpretation:
func (c *ComponentsSet) fillStatsd(cfg config.Config) {
if c.statsdClient != nil {
...
}
}
and then somewhere else:
func (c *ComponentsSet) fillGrpcConn(cfg config.Config) {
if c.grpcConn == nil {
...
}
}
state of ComponentsSet is dependent on configuration and in some cases components could be nil and in other not nil. Walking the AST is not enough. We won't know untill we evaluate the code. So I sadly had to leave some ifs in the code and handle them in the next stage.
Evaluation
Interpretation of the build function was the most complicated in the Go part of the project. It is evaluating each node in the AST recursively and building the dependency tree on the "way back". It's around 900 lines of dense Go code. I won't go into the details here, read the book to learn more.
Structure describing a dependency tree:
type dependency struct {
name string
deps []dependency
flatten bool
created string
importedFrom string
}
- name -
selector/identifier/constantused for creating this node. It can be something like:mongo.New,cfg.Mongo.Addr,append, - deps - dependencies of a given node,
- flatten - if this node should be removed from the final tree, nodes children are adopted by nodes parent, interpreter sometimes creates technical nodes that need to be removed at the end,
- created - debug string identifying place in code from which a node was created, for example:
BinaryExpr,KeyValueExpr,Ident, unknown,AssignStmt, there are 22 unique created identifiers, they proved very useful, - importedFrom - path of a package that this dependency was created from, used for linking to the repository in the frontend.
The hardest part was calling function calls, handing in arguments, passing receiver, extracting updates to receiver. I cut some corners here...
Enhancing
Enhancing was just a tree traversal which added values for nodes which are from configuration, repository URLs and file paths.
type EnhancedDependency struct {
Name string `json:"name"`
Deps []*EnhanceDependency `json:"deps,omitempty"`
Value interface{} `json:"value,omitempty"`
Url string `json:"url,omitempty"`
FilePath string `json:"file_path,omitempty"`
}
Rendering
At first I decided to render the tree with D2 into svg or png. At the beginning it was working, when I got to bigger builds, graphic files got too big. Browsers couldn't zoom close enough(500% is max) to see what was going on. Also tried different png or svg viewers, they all had problems.
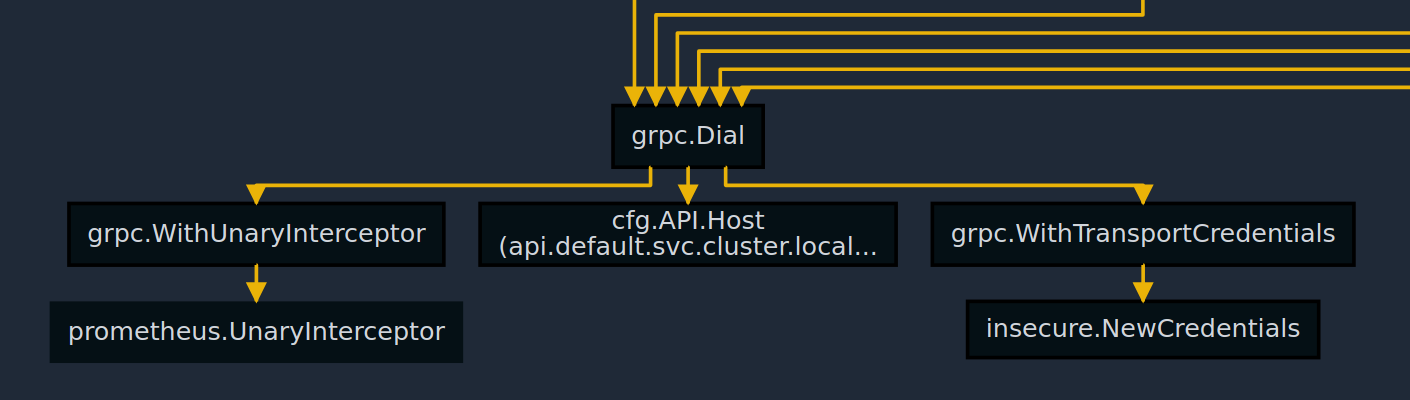
One of the problems was that I was rendering a tree, not a graph. Look at this code:
func Build(cfg config.Config) (Service, error){
grpcOptions := []grpc.DialOption{
grpc.WithTransportCredentials(insecure.NewCredentials()),
grpc.WithUnaryInterceptor(prometheus.UnaryInterceptor),
}
grpcConn := grpc.Dial(cfg.SomeService.Addr, grpcOptions)
...
c1 := some.Component(grpcConn)
...
c2 := otherComponent.New(grpcConn)
...
c3 := third.New(grpcConn)
...
}
The grpcConn is going to appear in a tree from the listing at least 3 times. There was way too much repetition in here. I tried combining all the nodes with the same names into a single node, but that didn't work. For example all append's got squished and the graph made no sense. I couldn't figure out how to fix this... Until I was describing the problem to a friend, I said "I need to combine subtrees that are the same", He repeated "subtrees that are the same?" and then it clicked. All I had to do was calculate hashes of each node using it and all its children. Nodes which have the same hashes should be combined into one node. I went with MD5 from json representation of a node. Tree became a graph.
And here is whole render, click to open it in new window:

At this point I had an image of the graph but it was still hard to read, follow the arrows and it was a bit overwhelming. It was missing interaction.
Frontend
Time to build a UI for interacting with the graph in the browser, using JavaScript. I have chosen bleeding edge, no build step, very powerful framework called static HTML file. HTML template file to be more precise. This was mostly dictated by simplicity and the way you integrate the project into your application.
This is how response body is built:
filled := strings.ReplaceAll(htmlTemplate, "{{GRAPH_DATA}}", graph)
filled = strings.ReplaceAll(filled, "{{MD5}}", md5str)
return []byte(filled), nil
}
There is an MD5 function(3.5k characters one liner) being injected into the HTML. I needed it to combine nodes, but placing it in HTML directly made my NeoVim really slow when it was on the screen. My guess is that it has something to do with treesitter color highlighting, but I'm not sure.
Building the frontend
With v0.dev I have generated HTML structure and tailwind classes needed to get started. I'm a backend engineer, I'm not good with HTML and CSS.
It was time to draw the graph. D2 could layout graphs with a couple of different engines, the ELK layouting engine was the best. I tried getting the same result using some JavaScript libraries for drawing graphs. Some of them even claimed to have the option of using ELK too, but it turned out that only for nodes but not for edges, the edges went straight through nodes... After 6 different libraries, around 20 hours spent during 2 weekends I got it working. JavaScript is great. I ended up using JointJS for drawing and ELK.js for layouting:
- create all nodes in JointJS with text inside them so node dimensions can be calculated,
- translate nodes and edges to ELK.js format and layout them with the library,
- translate result back to JointJS format with calculated positions of everything,
- draw the graph.
Next step was to add zooming and panning capabilities to the canvas on which the graph was drawn. I just used some library, it worked ok, after that I added tooltip for long names and edge highlighting for edges starting or ending at node above which the cursor is hovering.
After having all of this done, the rest of the process was straightforward. After all I was done with libraries and frameworks, add functionality, see that it works, add another one...
If you click on a node in the graph it gets highlighted. Things you can do with highlighted node:
- Focus - hides all nodes which are not between node and root, keeps the subtree starting from the node, basically hide everything not related to the highlighted node,
- Filter - hides node but keeps its children in the graph - hides not relevant nodes,
- Hide - hides node and all its children,
- Hide Children,
- Go To Repo - opens the source code package, from which the specified node originates, in a new tab,
- Copy package path,
There are also features not related to specific node:
- Filter by pattern - for example to hide every node containing
measuredin its name, - Show Given Root - for looking at top level components,
- Show all roots - go back to full view,
- Search.
The last feature ties everything together. Entire state of the view is captured in the URL. This allows you to create a direct link to the specific view you want someone else to see. There are still some bugs with URL, I know, I don't care.
Integration
One of the goals of this project was to make it as easy as possible to integrate with existing applications.
Arguments
To render a graph reflecting what is actually running in production, you need configuration used in production. That means creation of graphs needs to happen at runtime, after reading environmental variables. We need:
- configuration structure,
- entrypoint in the build package,
- build package code.
Library has this interface:
func New(
config interface{},
entrypoint string,
buildFS fs.FS,
options ...func(*Digraph),
) (*Digraph, error) {
Configuration needs to be a structure. Entrypoint is a string representation of how to find the function we want to analyze in build package. It's either a function name like Build or receiving struct + function name like Set.Build (Set of components). The interesting argument is build file system. During runtime we need source code to generate AST. I found a way to include files inside binary using Go's embed directive. Its main usage is to embed static files(like HTML or CSS) for self contained applications.
//go:generate rm -rf ./_build || true
//go:generate cp -r ../../internal/build ./_build
//go:embed _build/*
var buildPackage embed.FS
You can't embed files from parent directories, so I had to copy the build package, making it available locally. Starting directory name with _ makes go tooling ignore it, it works for gopls, linters, tests, etc. Also had to add _build to gitignore and add go generate ./... to Makefile in every application.
Handling HTTP
My library has function providing body and content type for HTTP response:
func (d *Digraph) Handler() func() ([]byte, string) {
All you need to do is wire Handler with your web framework of choice, for example with standard HTTP:
di, err := digraph.New(...)
...
handler := func(rw http.ResponseWriter, _ *http.Request) {
data, contentType := di.Handler()
_, _ = rw.Write(data)
rw.Header().Set("Content-Type", contentType)
}
http.HandleFunc("/graph", handler)
Putting it together
Final integrations might looks like this:
//main.go
import (
...
"github.com/user/project/pkg/digraph"
)
func main(){
var cfg configuration.Configuration
// fill the config
...
http.HandleFunc("/graph", digraph.Handler(cfg))
...
//pkg/digraph/digraph.go
package digraph
import (
"embed"
"io/fs"
"net/http"
"github.com/relardev/digraph"
)
//go:generate rm -rf ./_build || true
//go:generate cp -r ../../internal/build ./_build
//go:embed _build/*
var buildPackage embed.FS
func Handler(cfg interface{}) func(http.ResponseWriter, *http.Request) {
buildFS, err := fs.Sub(buildPackage, "_build")
if err != nil {
panic(err)
}
di, err := digraph.New(
cfg,
"Build",
buildFS,
)
if err != nil {
panic(err)
}
graphFunc := di.Handler()
handler := func(rw http.ResponseWriter, _ *http.Request) {
data, contentType := graphFunc()
_, _ = rw.Write(data)
rw.Header().Set("Content-Type", contentType)
}
return handler
}
Going to the /graph endpoint gives you the frontend: Click Me!
If you want to try using digraph let me know how it crashed or less likely, that it worked.
Whats next?
This project doesn't work for the general public, there are hacks and it doesn't support the whole Go spec. I'm experimenting with using off the shelf Go interpreter to generate the tree, so I don't have to write and maintain it myself.
Other related ideas:
- Service for aggregating all graphs and configurations from your applications and new deployments, graph diffs.
- Plugin for text editor that, given configuration, grays out the code not used by build, allows for jump to definition which goes to concrete implementation dodging the abstraction. Another feature could be marking each block of code in build with all configurations leading to its execution.
- Operation of dereferencing interface into concrete type is called Dynamic Dispatch. There is a cost associated with it. One could write a program to resolve interfaces during compile time and "bake" concrete structures into the codebase based on the configuration. Not sure how big the benefits could be, or if maybe Profile Guided Optimisation solves the problem, needs more research.
Thanks for reading. My stuff: links